Python is a language that embodies the philosophy “if it
walks like a duck and talks like a duck, it's a duck”, I know this is referring
to Python’s type mechanism, but Python is so intuitive, that whenever it walks
and talks like a duck, I just don’t think twice about it and assume it will
behave like a duck. That is why I am surprised that a script that runs well on
Windows fails mysteriously on Linux.
This script started out as a single-threading one, then I
tried to change it to use multiple threads using concurrent.futures.ThreadPoolExecutor,
it turned out, wait for it, the performance with multithreads was a disaster. This
is because the task my script does is very CPU-intensive, under this condition,
multi-threading is actually quite slower than single-threading. So I switched
to use multiprocessing.pool, it
worked like a charm on Windows: performance was improved greatly. The surprise
came when I deployed the script to Linux, all sorts of weird errors were thrown
out by SQLAlchemy (my script
uses SQLAlchemy to query and
save data in MySQL).
I researched into this, and found out multiprocessing behaves quite differently on Windows and
Linux, which is what I am going to share with you in this blog.
To simplify the research, I used two simple scripts:
- mppool_0.py
- mppool_1.py
mppool_1.py is
very simple, and is imported into mppool_0.py,
we just want to find out when and how this script will be imported by the main
script.
import os
print("imported by process:"+str(os.getpid()))
gv1=25
mppool_0.py is
the main script:
import mppool_1 import os from random import randint gv=None def longRunningFunc(n): import time time.sleep(randint(1,10)) print("in process:"+str(os.getpid())+" global variable is:"+str(gv)) mppool_1.gv1 +=mppool_1.gv1 print("in process:"+str(os.getpid())+" global variable in imported is:"+str(mppool_1.gv1)) return n def _workInitialize(): print("initialize:"+str(os.getpid())) def work(): from multiprocessing import Pool pool = Pool(processes=2, initializer=_workInitialize) ret=pool.map(longRunningFunc,range(4)) print("pool is finished") print(ret) gv=5 print("invoked before __main__block by process:"+str(os.getpid())+" global variable is:"+str(gv)) if __name__ == '__main__': gv=6 print("invoked in __main__ block by process:"+str(os.getpid())+" global variable is:"+str(gv)) work()
Some basic knowledge:
- pool = Pool(processes=2, initializer=_workInitialize) starts two processes, which will be initialized by function _workInitialize. If processes parameter is not given, Pool will start as many process as the number of CPUs.
- pool.map(longRunningFunc,range(4)) , longRunningFunc is the task that will be run by child-processes, the second parameter is an array, the length of the array is the count of tasks, each element of the array will be passed to longRunningFunc as its parameter. In this example, there will be 4 tasks run by 2 processes.
- pool.map() is synchronous, it will wait until all child processes have finished. The return value is the results from all child processes.
- __name__ is a special variable. If the python interpreter is running the module as the main program, it sets the __name__ to "__main__". If this file is being imported from another module, __name__ will be set to the module's name.
Let us compare the outputs from running Windows and Linux
(left is Windows, right is Linux):
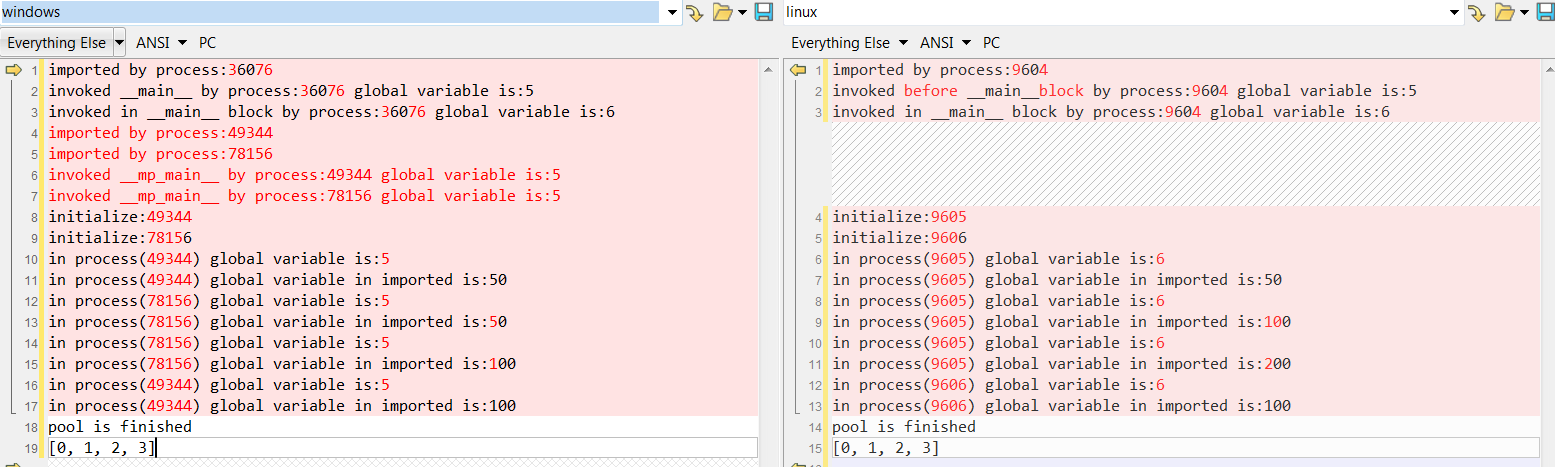
Let us first check out things that are the same:
- Both starts two child-processes
- Tasks are assigned to these 2 child-processes. Child-processes behaves like threads, after they finish one task, they get another. On the left, every child-process gets to execute two tasks; on the right, one child-process runs faster, and it gets to run 3 tasks.
- Unlike multithreading, multi-process won’t have data-contention issues. But since child-processes are recycled, be careful how you modify your data, which will be carried to the next round of running the child-process. In this example, you can see variable mppool_1.gv1 is updated in subsequent runs.
Now let us check the differences:
- Through the output, we can see on Windows, a child-process runs the same program as the main-process: it also imports mppool_1.py, and sets the global variable gv to 5. if __name__ == '__main__' prevents child-processes from entering in, as for child-processes, __name__ is set to “__mp_main__”, so things inside the if __name__ == '__main__' block is only run by the parent process.
On Windows, Pool has to be configured with if __name__ == '__main__' block, otherwise, the script will simply run into a cycle with the following error thrown out:
RuntimeError:An attempt has been made to start a new process before thecurrent process has finished its bootstrapping phase.This probably means that you are not using fork to start yourchild processes and you have forgotten to use the proper idiomin the main module:if __name__ == '__main__':freeze_support()...
- On the other hand, on Linux, a child-process starts its life at the point when the parent process starts it and inherits everything from the parent process. In this example, a child-process doesn’t import mppool_1.py, but it can still access it as it inherits it from the parent process; it doesn’t set variable gv to 5, and when it runs, it sees variable gv as 6, not 5 because the parent process has changed gv to 6 before the parent process starts child-processes.
This means, on Linux, you do not need to place Pool setup inside if __name__ == '__main__' . But you still should do it for cross-platform compatibility.
This difference is because on Linux, multiprocesses uses fork() to start a
child-process, which inherits the memory status of the parent process. On
Windows, there is no fork(),
so a child-process starts running from scratch.
The differences in this example is easy to understand, but
back to my script which prompted me to do the research in the first place, my
script uses a SQLAlchemy.engine()to
query/insert into MySql, in
Windows, it works fine, sudo code is like the following:
def work():pool=Pool()pool.map(_longRunningFunc)def _longRunningFunc(n): #this is the task run by each child processDBUtil.engine.execute()…. # use engine to do some mysql stuffDBUtil.init () #initializes SQLAlchemy.engine()if __name__ == '__main__'work()
In windows, every child process gets to run DBUtil.init
(), and gets to initialize SQLAlchemy.engine(), so everything works
out ok. In Linux, SQLAlchemy.engine() is actually shared by all processes.
Behind the scene, SQLAlchemy.engine() maintains a pool of connections, a
connection is a physical tcp/ip connection with the MySQL database, when
they are shared across processes, all weird things happen.
Initialize a process is easy, as Pool()has a parameter initializer,
what is tricky is there is Pool() doesn’t provide finalizer.
And this turns out to be another big difference between Windows and Linux.
Let us continue to use the two simple scripts as an example.
On windows, cleanup a process is easy, just add the
following at the end of mppool_0.py, and you shall see all 3
processes (the 2 child processes and the parent process) run the exit_hanlder()function when they exit.
def exit_handler(): print("finished process:"+str(os.getpid())) import atexit atexit.register(exit_handler)
This however, doesn’t work on Linux. After digging through multiprocessing
code, the reason is on multiprocessing/popen_fork.py file:
def _launch(self, process_obj):
code = 1
parent_r, child_w = os.pipe()
self.pid = os.fork()
if self.pid == 0:
try:
os.close(parent_r)
if 'random' in sys.modules:
import random
random.seed()
code = process_obj._bootstrap()
finally:
os._exit(code)
else:
os.close(child_w)
util.Finalize(self, os.close, (parent_r,))
self.sentinel = parent_r
Child process is ended with os._exit(), on https://docs.python.org/2/library/atexit.html,
it is clearly said: The
functions registered via this module are not called when the program is killed
by a signal not handled by Python, when a Python fatal internal error is
detected, or when os._exit()
is called.
So how can we clean up a child process? This actually took
me quite some time to dig through multiprocessing
code, and the clue is on multiprocessing.util.Finalizer:
def __init__(self, obj, callback, args=(), kwargs=None, exitpriority=None):
assert exitpriority is None or type(exitpriority) is int
if obj is not None:
self._weakref = weakref.ref(obj, self)
else:
assert exitpriority is not None
self._callback = callback
self._args = args
self._kwargs = kwargs or {}
self._key = (exitpriority, next(_finalizer_counter))
self._pid = os.getpid()
_finalizer_registry[self._key] = self
Finalizer will
register itself into _finalizer_registry,
and upon existing, all registered finalizers will be executed; Finalizer also has a weakref, the
callback method will be called when the weak-referenced object is to be
finalized.
The complete solution is as follows:
import mppool_1
import os
from random import randint
gv=None
class Foo:
pass
def longRunningFunc(n):
import time
time.sleep(randint(1,10))
print("in process:"+str(os.getpid())+" global variable is:"+str(gv))
mppool_1.gv1 +=mppool_1.gv1
print("in process:"+str(os.getpid())+" global variable in imported is:"+str(mppool_1.gv1))
return n
foo=Foo()
def exit_handler():
print("finished process:"+str(os.getpid()))
def _workInitialize():
print("initialize:"+str(os.getpid()))
from multiprocessing.util import Finalize
#create a Finalize object, the first parameter is an object referenced
#by weakref, this can be anything, just make sure this object will be alive
#during the time when the process is alive Finalize(foo, exit_handler, exitpriority=0) def work(): from multiprocessing import Pool pool = Pool(processes=2, initializer=_workInitialize) # ret=pool.map(longRunningFunc,range(4)) print("pool is finished") print(ret) gv=5 print("invoked before __main__block by process:"+str(os.getpid())+" global variable is:"+str(gv))
# A tip to debug multiprocessing, you can use the following to enable the package to log details
from multiprocessing import util
util.log_to_stderr(util.SUBDEBUG)
if __name__ == '__main__':
gv=6
print("invoked in __main__ block by process:"+str(os.getpid())+" global variable is:"+str(gv))
work()
#parent process will get to call ateixt
import atexit
atexit.register(exit_handler)
PS: my python version is:
vagrant@stock:/stock$ python --version
Python 3.5.2 :: Anaconda 4.2.0 (64-bit)
No comments:
Post a Comment